If you’ve been following me recently you might recall that I’ve been chasing an issue with a Motorola WS5100 running v3.3.5.0-002R experiencing high CPU utilization. The problem came to a head this weekend and here’s my quick account of the experience.
The WS5100 would intermittently come under extreme load for 5-30 minutes, so much load that ultimately the entire wireless network would collapse as the Access Ports started experiencing watchdog resets and would just continually reboot themselves. This problem would come and go throughout the day or night, we could go 12 hours without an issue and then go the next 12 hours with issues every 30 minutes. The problem was affecting both the primary and secondary WS5100 so I eliminated the hardware almost out of the gate. I have first hand experience running v3.3.5.0-002R software on a large number of WS5100s and have never had an issue with that software release so I really didn’t suspect the software. This wireless solution had been in place for more than 18 months without any major issues or problems. The local engineers reported that there had been no changes, no new devices. So what was causing this problem? I immediately suspected an external catalyst but how would I find it?
As with most highly technical problems it wasn’t until I could get my hands on some packet traces and I had time to dissect those packet traces that I could start to fully understand and comprehend what was actually going on.
Topology
A pair of Motorola WS5100 Wireless LAN Switches with 30 AP300 running software release v3.3.5.0-002R in a cluster configuration with one running as primary and the other running as secondary. The network was comprised of a single Cisco Catalyst 4500 with around ten individual Cisco Catalyst 2960S switches at the edge each trunked to the core in a simple hub and spoke design. The entire network was one single flat VLAN. The WS5100s were attached to the Cisco Catalyst 4500 via a single 1Gbs interface, one arm router style. The peak number of wireless devices was around 200, the total number of MAC addresses on the network was around 525 (this includes the wireless devices).
Symptoms
The initial problem report centered around poor wireless performance and sure enough I quickly found 30-40% packet loss while just trying to ping the WS5100. When I finally got logged into the WS5100 I could see that the CPU was running at 100%. The SYSLOG data showed me that the APs were rebooting because of watchdog timeouts. PTRG was showing me that here was a huge traffic surge being received from the WS5100. I quickly realized that the traffic spikes in the graph correspond to events that users were experiencing problems.
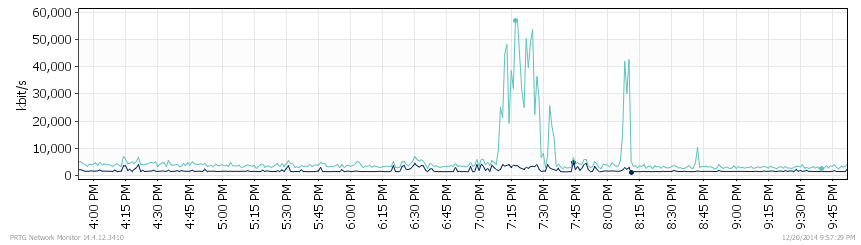
Packet Traces
I directed the team to setup a SPAN port to capture the traffic that was flowing between the WS5100 and the Cisco Catalyst 4500 switch. This would provide me a better idea of what was actually on the wire and might provide a clue as to what was transpiring. The team setup Wireshark to continually capture to disk using a 100MB file size and allowing the file to wrap 10 times for a total of 1GB of captured data. The next time the problem occurred I was alerted within 15 minutes by the help desk and users but I found that we missed the start of the event. There was so much traffic Wireshark only had the past 3 minutes available on disk so we had to increase the filesize to 300MB and the number of wrap files to 25 giving us a total capacity of 7.5GB. That configuration would eventually allow me to capture the initial events along with the time needed to get to the laptop and copy the data before it was overwritten. While I waited for the problem to occur I took to setting up SWATCH to alert myself and the team when the problem started so we could quickly gather all the data points during the start of the event.
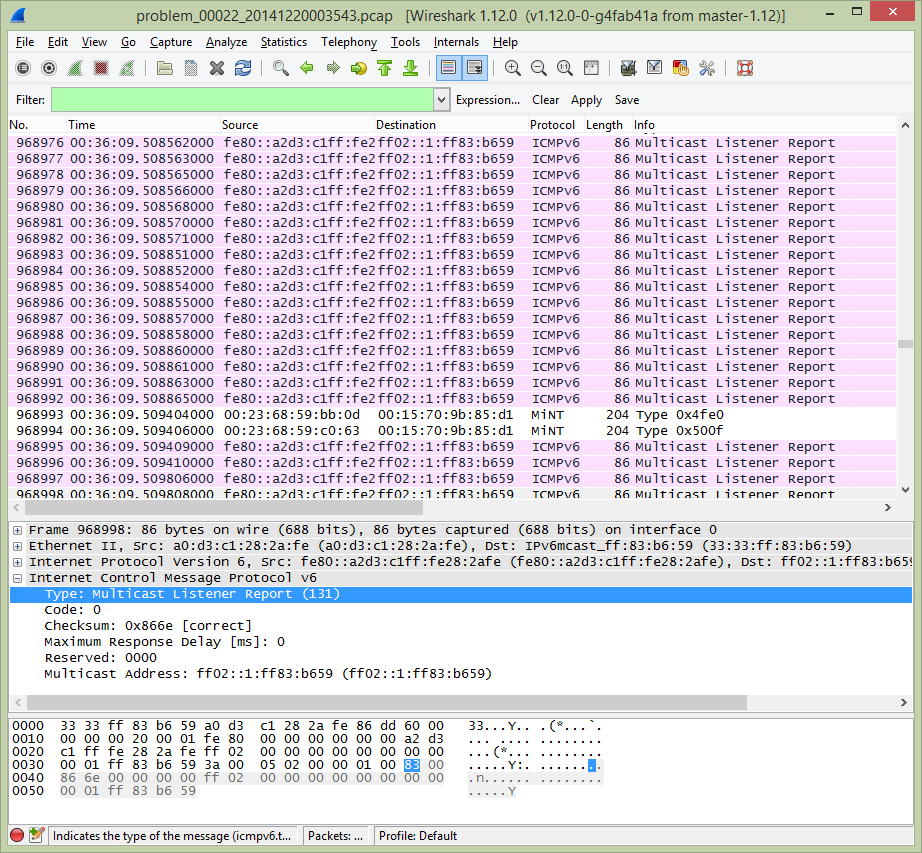
Using the data from the packet traces we were able to identify and locate two HP desktops that were apparently intermittently flooding the network with ICMPv6 Multicast Listener Reports.
We removed those HP desktops from the network and everything has been stable since.
Analysis
Here’s the current working theory which I believe is fairly accurate. The HP desktops were intermittently flooding the network with ICMPv6 Multicast Listener Reports. Those packets were reaching the WS5100 and because the network at this location is a single flat VLAN the WS5100 needs to bridge those packets over to the wireless network. It does this by encapsulating them in MiNT in a fashion very similar to CAPWAP or LWAPP. The issue here is the number of packets and the number of access points or access ports. In this case we had 30 APs connected to the WS5100 so let’s do some rough math;
41,000 ICMPv6 Multicast packets * 2 HP desktops = 82,000 packets * 30 APs = 2,460,000 packets
This explains the huge amount of traffic the WS5100 is transmitting. For every ICMPv6 Multicast packet (or broadcast packet for that matter) received by the WS5100, it needs to encapsulate and send a copy of that packet to each and every AP. If there are 30 APs then the WS5100 needs to copy each and every packet 30 times. Now multiply that by the number of ICMPv6 packets that were being received by the WS5100 and you have a recipe for disaster.
A quick search of Google will reveal a number of well documented issues with Intel NICs.
The HP desktops turned out to be HP ProDesk 600 G1s running Windows 7 SP1 with Intel I217-LM NICs driver v12.10.30.5890 with sleep and WoL enabled.
Summary
There were a few lessons learned here;
- The days of the single flat network are gone. It’s very important to follow best practice when designing and deploying both wired and wireless infrastructures. In this case if the wireless infrastructure had dedicated VLANs both for the wireless client traffic and for the AP traffic this problem would have never impacted the WS5100. It may have impacted the Cisco Catalyst 4500 somewhat but it wouldn’t have caused the complete collapse of the wireless infrastructure. Unfortunately in this case everything was on VLAN 1, wired clients, APs, wireless clients, servers, IP phone systems, routers, everything.
- The filtering of IPv6 along with Multicast and broadcast traffic from the wireless infrastructure is especially important. I posted back in September 2013 how to filter IPv6, multicast and broadcast packets from a Motorola RFS7000, the same applies to the WS5100. Unless you are leveraging IPv6 in your infrastructure, or have some special multicast applications you should definitely look into filtering this traffic from your wireless network.
- Validate those desktop and laptop images, especially the NIC drivers and WNIC drivers. In the early days of 802.1x I can remember documenting a long list of driver versions and Microsoft hotfixes required for Microsoft Windows XP (pre SP2) in order to get 802.1x authentication (Zero Wireless Configuration) to work properly.
Conclusion
Wireshark saved this network engineer’s holiday – Thanks!
Cheers!
Note: This is a series of posts made under the Network Engineer in Retail 30 Days of Peak, this is post number 27 of 30. All the posts can be viewed from the 30in30 tag.
Sounds awfully similar to the meltdown that MIT CSAIL had a few months back:
http://blog.bimajority.org/2014/09/05/the-network-nightmare-that-ate-my-week/
I suspect this won’t be the last growing pain that IPv6 has in store for enterprise networks…
Thanks for the comment Frank,
I too read Garrett’s post a few months back… was very interesting and definitely a warning sign for network engineers and administrators as IPv6 starts to take hold.
In this case there’s a known issue with the Intel I217-LM NIC driver that I believe is the ultimate culprit.
Cheers!
Of note, the Multicast Listener Report floods were triggered by the desktops going into sleep mode (the bug is connected to IPv6 Wake On LAN) hence explaining the seemingly random nature of floods. Great write up Mike.
Hi Joe,
You are correct…
Once I was able to get some sleep (very long weekend) I went back and looked at the logs and data we had collected and sure enough the problem only occurred between 7PM and 8AM on the nights in question. We went back and confirmed that both HP desktops were configured to sleep and had Wake-On-LAN enabled within the BIOS. As your alluding to there are quite a few articles on the Internet detailing this exact same problem. Now I’m wondering what’s the fix? A Windows driver upgrade, a BIOS upgrade?
Thanks for the comment!
According to this: https://communities.intel.com/message/220048, driver upgrade should fix it.
Glad you got some rest!