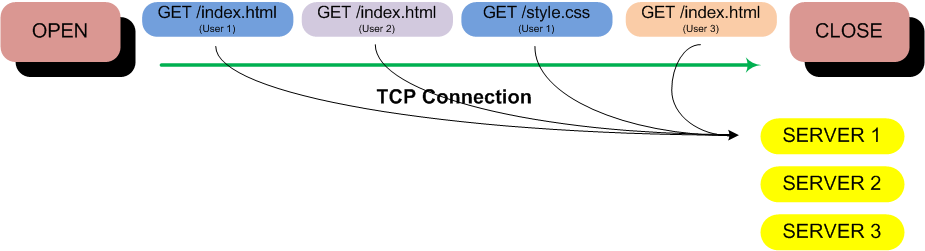
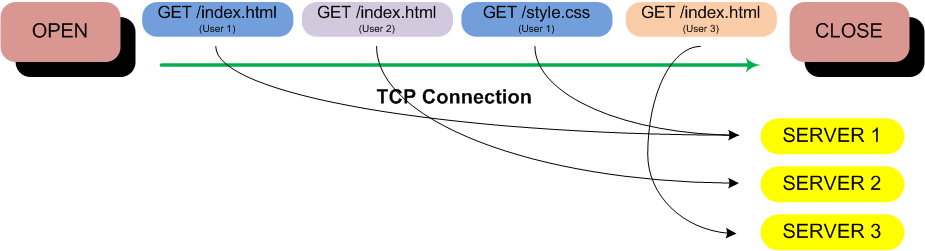
I’ve recently found myself dealing with a lot of storage area network issues. It’s my team that has the privilege of maintaining 22 different Fiber Channel Storage Area Network (SAN) switches with multiple independent and redundant SAN fabrics. I’ve recently run into a number of situations where improper cabling and FC SAN switch zoning were the root cause to some very visible application outages. A SAN provides “block” level access to a multitude of devices including disk arrays such as the EMC VNX 5300 and 7500, and tape drives such as the HP MSL 4048 tape library. Storage Area Networks provide centralized storage and usually play an important role in cluster solutions due to their ability to share storage between multiple servers or hosts. If you have a traditional (non-VSAN) VMware ESXi cluster you have either a Fiber Channel or iSCSI SAN providing the VMware datastores between the ESXi hosts.
A few weeks ago I had the opportunity to expand the SAN fabric by installing a pair of Brocade 5100 FC SAN switches. You need to follow a pretty simple process to ISL a FC SW to an existing SAN fabric.
- You must make sure that the new switch has a unique Domain ID in relation to all the other switches in the fabric
- You must make sure make that the new switch doesn’t have an active ZONE configuration
- With those two steps completed you only need to physically connect the switches.
The switches will automatically configure the FC ports as E-Ports and establish an Inter Switch-Link (ISL) trunk between the two FC switches. The ZONE configuration will be copied over to the new switch so there’s very little to-do beyond configuring an IP address for management.
Whether you have a large storage network or you just have a single FC switch you might want to look at Brocade SAN Health.
I was very surprised by the level of detail that the tool was able to capture, and the Visio diagram was awesome!
I also took the opportunity to do some housekeeping by going back through all the FC switches and make some general configuration changes enabling SNTP, setting the timezone and configuring SYSLOG logging. I can’t tell you how maddening it is trying to troubleshoot a problem where the log time stamps are all wrong. Here are the CLI commands that I used to make those configuration changes;
tsTimeZone US/Eastern tsclockserver 1.2.3.4 syslogdipadd 1.2.3.4
While changing the timezone the switch reported that I needed to reboot the switch for the change to take affect. I have yet to reboot the switch but the time is reporting the correct offset from GMT. This message was consistent across all versions of Brocade’s Fabric OS including v6.x and v7.x.
Cheers!